- 发布于
论文阅读笔记
- 作者

- 姓名
- Corner430
- 社交账号

本文整理了我在学习过程中阅读的多篇论文笔记,涵盖 Transformer 架构、目标检测、视觉识别、知识蒸馏、自监督学习等方向。
目录
- Attention Is All You Need:Transformer
- End-to-End Object Detection with Transformers:DETR
- AN IMAGE IS WORTH 16X16 WORDS:Vision Transformer
- Incremental-DETR:增量小样本目标检测
- Lightweight Transformer for Multi-Modal Object Detection
- Self-supervised Label Augmentation via Input Transformations
- Learn More for Food Recognition via Progressive Self-Distillation
- Solving Math Word Problems with GPT-3
- Curriculum Temperature for Knowledge Distillation
- Sharpness-Aware Minimization(SAM)
- Adaptive Hierarchy-Branch Fusion for Online Knowledge Distillation
- Peeling the Onion
- Class Incremental Learning with Contrastive Distillation
- Improving Face Recognition via Random Temperature Scaling
- De-biased Teacher for Semi-supervised Object Detection
- Grouped Knowledge Distillation for Deep Face Recognition
泛读笔记
Can Bad Teaching Induce Forgetting?
论文链接:Can Bad Teaching Induce Forgetting? Unlearning in Deep Networks Using an Incompetent Teacher
本文角度新颖,利用知识蒸馏使模型「变弱」,有意遗忘某些知识。应用场景例如:某些数据授权到期,需要让模型遗忘相关知识。传统方法是重新训练,而本文提出用「无能教师」进行蒸馏来实现遗忘。
SKDBERT:随机知识蒸馏压缩 BERT
论文链接:SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
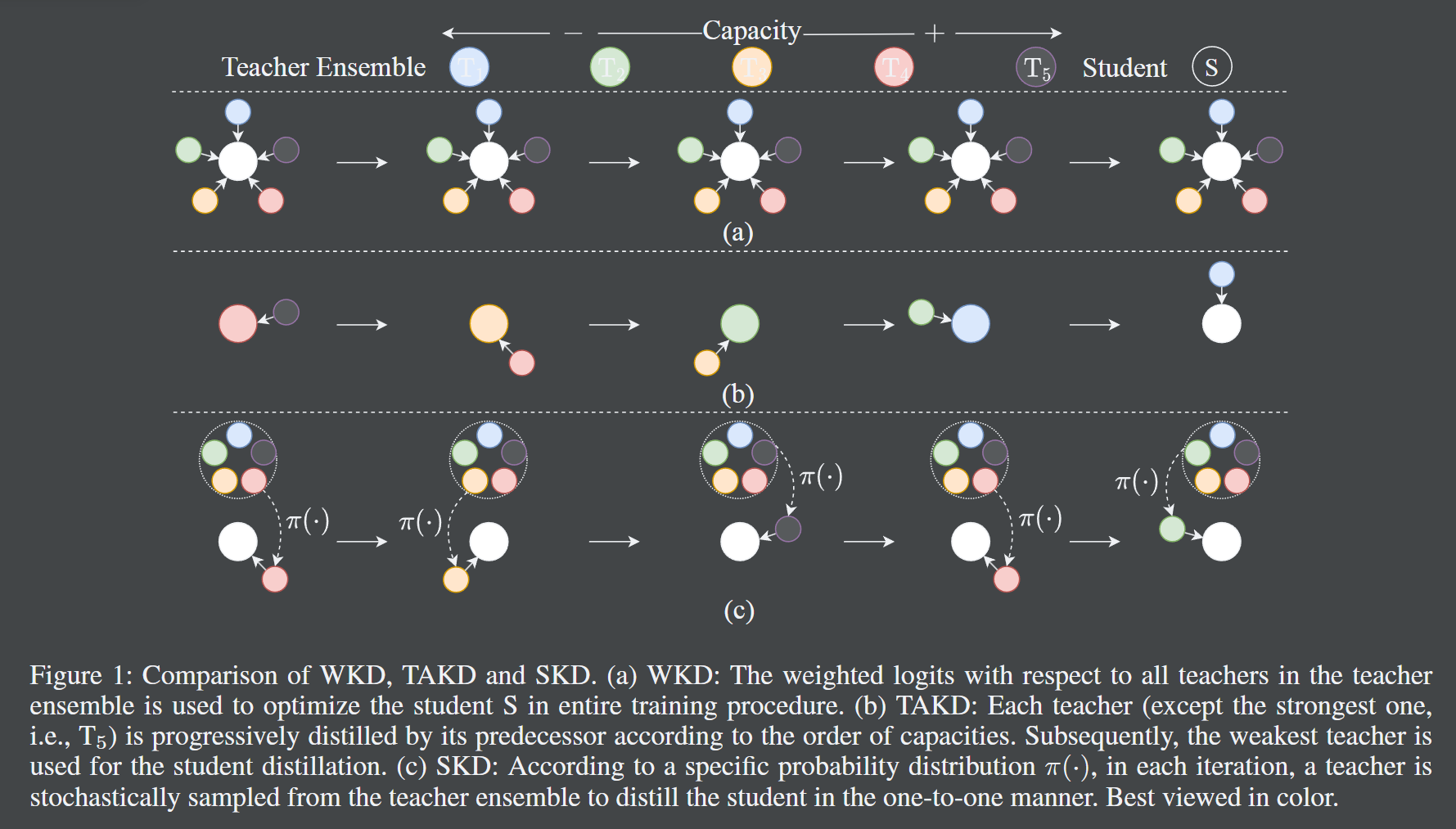
本文采用随机知识蒸馏方法:每次迭代从多个具有不同容量层级的教师中随机选择一个进行蒸馏。在能力基本无损的情况下,模型体积减少了 40%。
BGNN:自适应知识蒸馏增强图神经网络
论文链接:Boosting Graph Neural Networks via Adaptive Knowledge Distillation
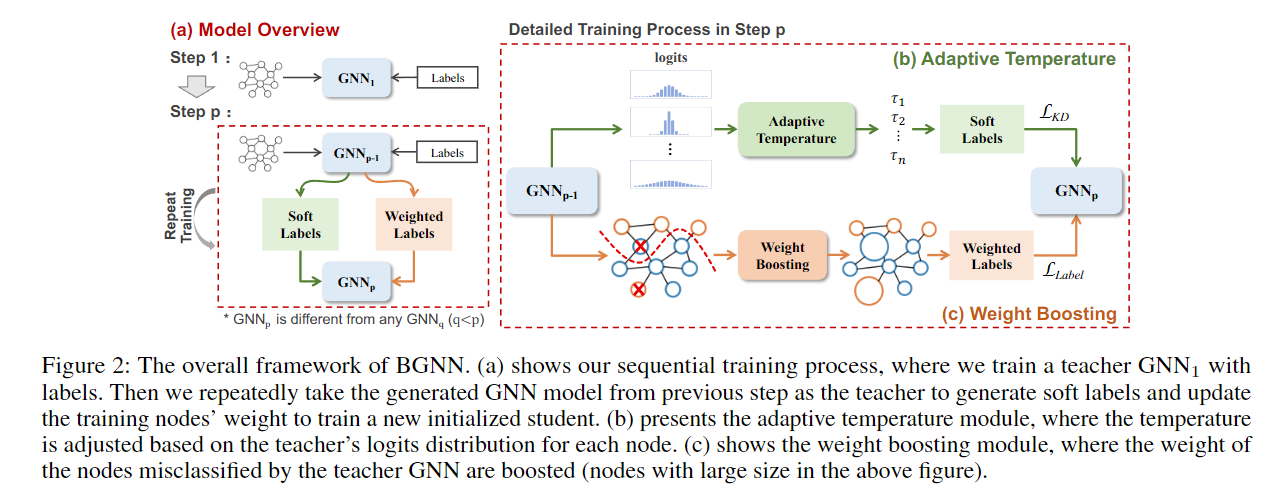
本文提出 BGNN 框架,利用多个图神经网络(GNN)的互补知识来提升学生 GNN 的性能。核心思想:对于同一个 GNN,不同聚合方式会学到不同知识,通过知识蒸馏实现互补。
主要创新:
- 自适应温度模块:根据教师模型对不同节点的 logits 分布(具体依据节点对应的梯度值)动态调整温度。
- 权重提升模块:对分类错误率高的节点赋予更高权重。
实验结果:在节点分类和图分类任务上分别提升了 3.05% 和 6.35%。
正文
1. Attention Is All You Need:Transformer
先修知识:BLEU 评估指标
BLEU(Bilingual Evaluation Understudy)是机器翻译质量评估指标,通过计算机器翻译与参考翻译之间的 n-gram 匹配程度来衡量翻译精确度。取值范围 0 到 1,越接近 1 越好。
其中 BP 为简短惩罚因子:
为机器翻译总长度, 为参考翻译的最佳匹配长度。 为基于 n-gram 的改进精确度:
权重 一般取均匀值 , 通常为 4。
简介
本文发表于 2017 年,提出 Transformer 结构——完全基于注意力机制,不使用 CNN 和 RNN,因此可以并行计算。
- 数据集:
- WMT 2014 English-German:约 4.5 万对英德语句子
- WMT 2014 English-French:约 35 万对英法语句子
- 代码:tensor2tensor
核心贡献
- 前人的序列转换模型基于 RNN 或 CNN,本文提出仅基于注意力机制的 encoder-decoder 结构。
- 在 BLEU 指标上取得最优效果。
- 在 8 块 P100 GPU 上训练 12 小时。
背景
- RNN 需要顺序计算,无法并行。
- 前人方法未解决长距离依赖学习问题:距离越长,计算量越大。
- Transformer 通过 embedding 固定维度,并用 multi-head attention 弥补可能的信息损失。
模型架构
沿用 Encoder-Decoder 结构,其中 Decoder 是自回归的(当前输入依赖前面的输出)。
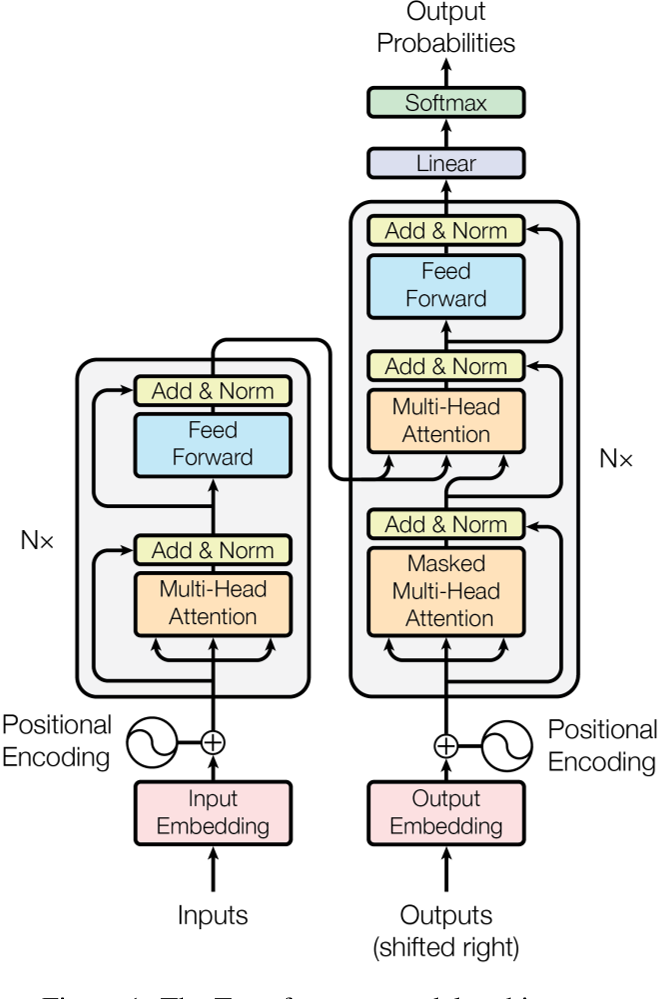
Encoder:
- 层,每层包含两个子层:multi-head self-attention 和 position-wise FFN
- 每个子层有残差连接 + Layer Normalization
- 为满足残差连接,embedding 和输出维度均为
Decoder:
- 层,每层包含三个子层:masked multi-head self-attention、multi-head attention 和 position-wise FFN
- K(键)和 V(值)来自编码器输出,Q(查询)来自解码器输出
- masked self-attention 通过将后续位置掩码为负无穷来防止信息泄露
注意力机制
Scaled Dot-Product Attention:
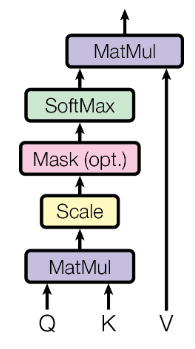
queries 和 keys 维度为 ,values 维度为 。除以 是为了消除方差的影响。点积注意力比加性注意力效率更高。
Multi-Head Attention:
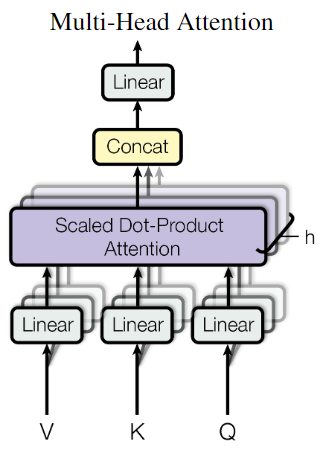
将 queries、keys、values 分别映射到 维空间( 个头),分别执行注意力计算后拼接,再映射回 维。
注意力的应用
- 解码器中,queries 来自前一个解码层,keys 和 values 来自编码器输出
- 编码器包含 self-attention
- 通过 mask 防止解码器访问后续位置
前馈网络
输入输出维度 ,中间层维度 。
Embedding 与位置编码
- input embedding 和 output embedding 共享参数
- 权重乘以 使 embedding 结果方差为 1(参考 分析)

位置编码使用正弦和余弦函数:
为什么用 Self-Attention?
- 可并行计算
- 远距离词也能直接交互
- 还可以使用局部注意力
实验结果
大模型在 8 块 P100 GPU 上训练 3.5 天:
总结
- 提出完全基于注意力机制的 Transformer,可并行计算
- 在机器翻译任务上取得最优效果
- 未来方向:局部注意力、图像/音频领域的应用
2. DETR:端到端目标检测
论文链接:End-to-End Object Detection with Transformers
先修知识
匈牙利算法:用于解决指派问题的经典算法。
核心贡献
- 将目标检测视为集合预测问题,去除 NMS、anchor、proposals 等,真正实现端到端
- 性能对标 Faster R-CNN
- 数据集:COCO
- 代码
设计思路
传统方法先生成 proposals 再分类再回归,结果受限于中间操作。DETR 使用 Transformer 并行输出结果,无需自回归。
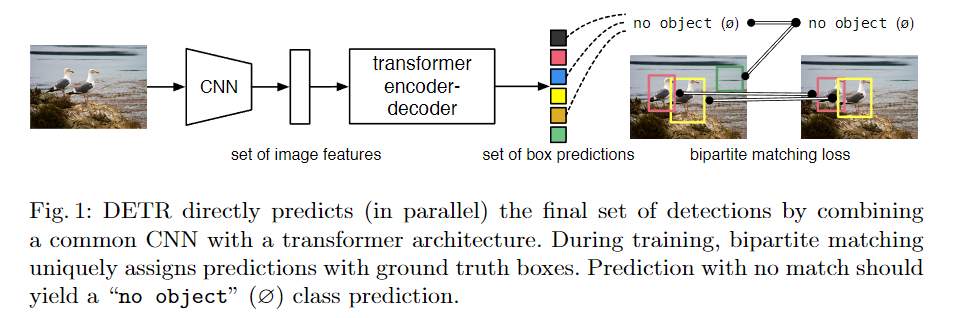
- 使用二分匹配损失(bipartite matching loss)
- 大物体效果好,小物体效果稍差
- 可扩展到全景分割
模型架构
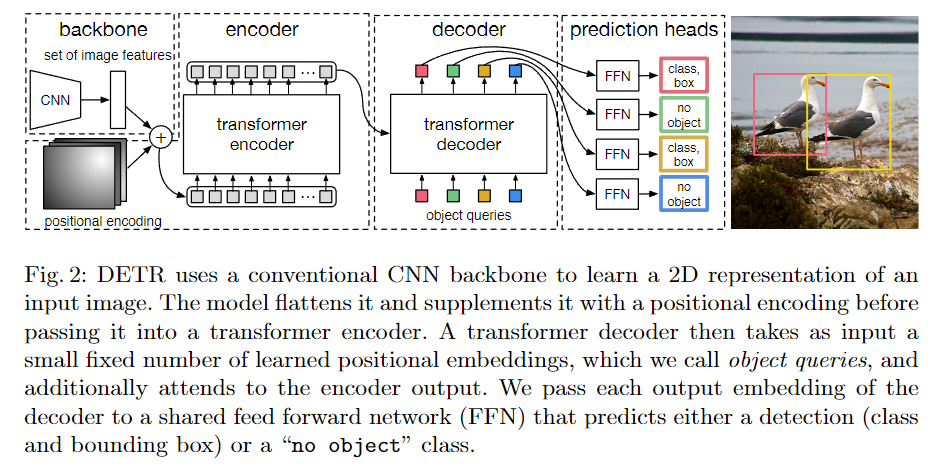
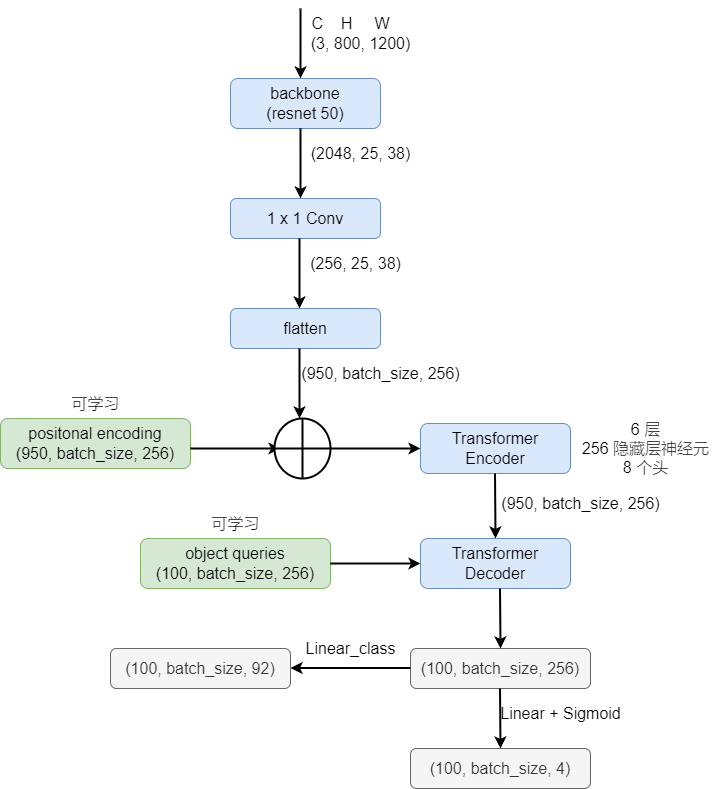
- object queries:100 个固定的可学习向量,表示目标个数
- 匹配代价同时考虑类别和边界框信息
- 仅对非空类别计算损失
损失函数
首先通过 一对一匹配预测框与真实框:
其中 为真实标签, 为类别(可为空), 为边界框。
边界框损失使用 L1 损失和广义 IoU 损失的组合:
匈牙利损失:
匹配代价未使用对数,而匈牙利损失使用了对数——两者关注的优化目标不同:前者关注数值平衡,后者关注梯度平衡。
- positional encoding 和 object queries 加入每层 attention 的计算
- 使用辅助解码损失(每层输出都计算损失,所有 FFN 共享参数)
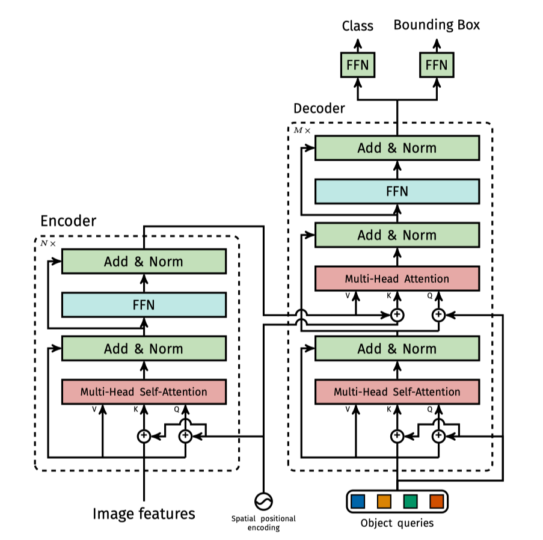
3. Vision Transformer(ViT)
论文链接:AN IMAGE IS WORTH 16X16 WORDS
代码:vision_transformer
将未修改的 Transformer 直接应用于图像分类存在困难:图像是二维矩阵,直接展平为序列会导致序列过长。
ViT 的解决方案:将图像划分为 个 patch,每个 patch 维度为 ,作为一个 token 输入 Transformer。额外添加一个 class token 用于分类。
4. Incremental-DETR:增量小样本目标检测
论文链接:Incremental-DETR
代码:Incremental-DETR
问题定义
- 学习新类别时,基类数据不可用
- 新类和旧类无重叠
- 新类仅有少量样本
方法
第一阶段:基模型训练
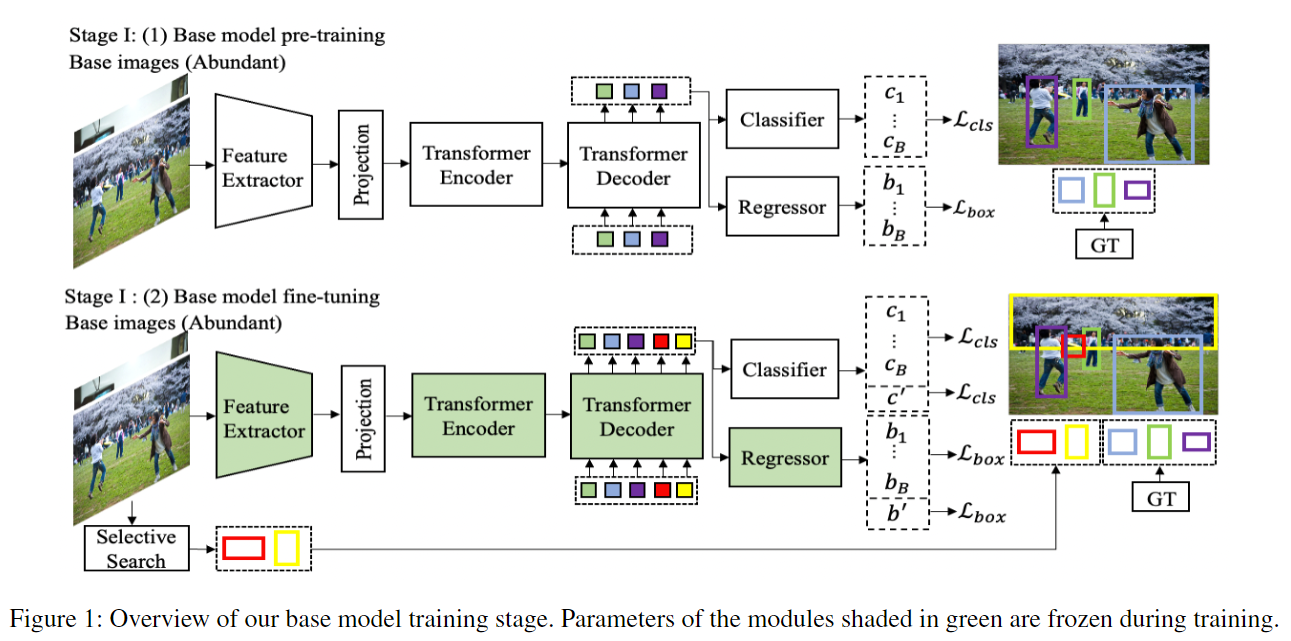
- 在 上正常训练 DETR
- 通过 selective search 生成 proposals,选择与基类 ground truth 不重叠的 top-O 个作为伪标签进行自监督微调
第一阶段损失:
第二阶段:增量微调
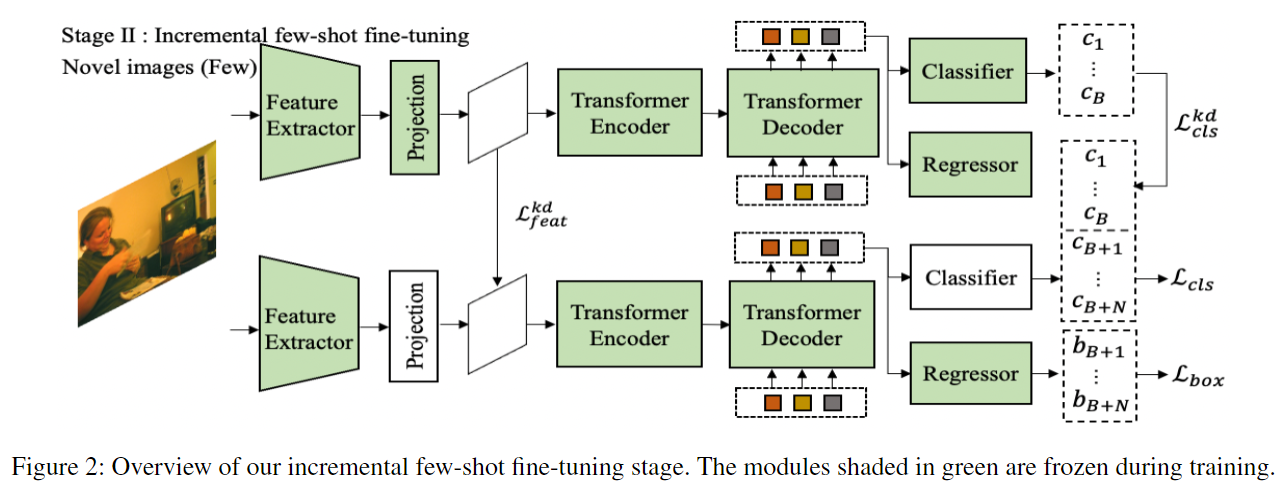
经验发现:投影层和分类头是类相关的,CNN 主干、Transformer 和回归头是类无关的。仅对类相关部分进行微调。
为防止灾难性遗忘,引入带掩码的知识蒸馏:
对于分类器头,使用 KL 散度蒸馏:
第二阶段总损失:
总结
- 通过蒸馏实现新知识学习与旧知识保持的平衡
- 自监督生成新类伪标签,使模型更易接受新知识
- 将模型参数分为类相关和类无关两部分
5. 轻量级多模态目标检测 Transformer
论文链接:Lightweight Transformer for Multi-Modal Object Detection
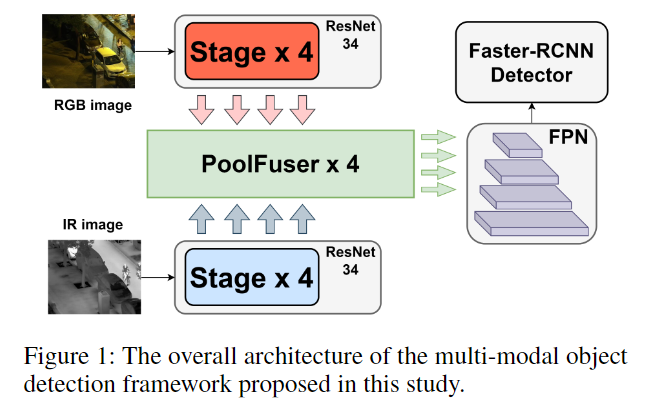
多模态融合(如自动驾驶中的多传感器)面临精度与速度的权衡。本文提出 Poolformer-based fusion operator,用池化替代传统的权重分配方式,在减少参数量、提高速度的同时保持效果。
参考代码:transfuser
6. 自监督标签增强(SLA)
论文链接:Self-supervised Label Augmentation via Input Transformations
代码:SLA
核心思想:通过数据增强来增强标签,不仅对无监督和半监督学习有效,对全监督学习也能带来提升。将「共享底层特征」改为「统一任务」。
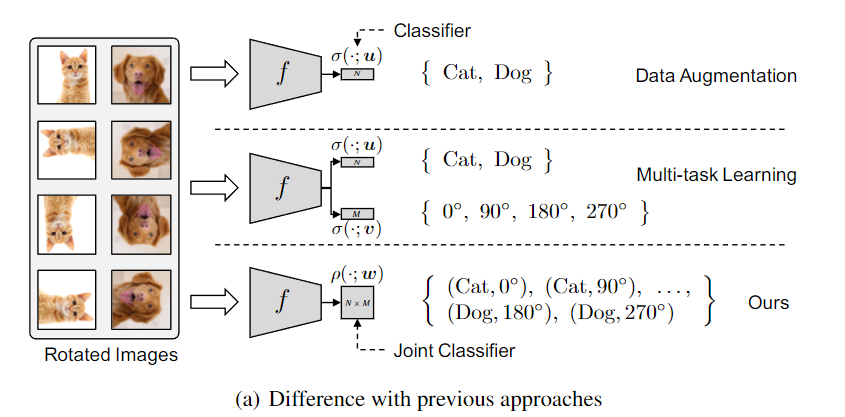
三种方法对比:
- 数据增强(DA):仅变换输入,强制标签不变。存在弊端(如 6 和 9 的旋转)。
- 多任务学习(MT):同时优化原始任务和自监督任务,但在全标签数据上通常无额外提升。
- SLA:直接学习联合概率分布,效果最好。
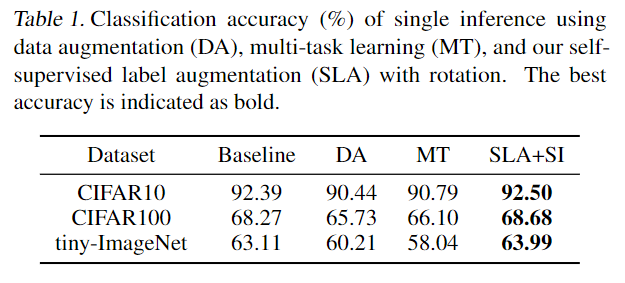
SLA 仅增加标签数量,对模型参数基本无影响。它可以退化为数据增强或多任务学习,但多任务学习约束过强(强制标签不变),难以优化。
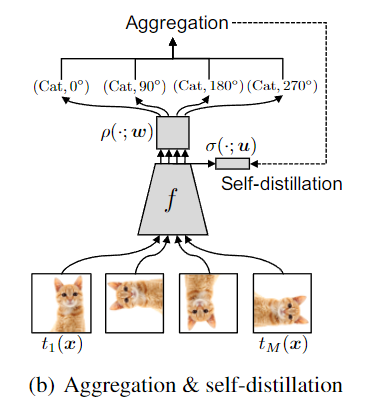
预测结果变为 倍后,先做聚合(将 个条件概率相加),再经 softmax 后与原标签计算蒸馏损失:
7. 渐进式自蒸馏用于食品识别(PSD)
论文链接:Learn More for Food Recognition via Progressive Self-Distillation
食品识别是细粒度分类中的难题——食品可能由多种食材堆叠构成(如沙拉),传统弱监督定位方法受限于区域定位的精度。
PSD 方法:教师模型和学生模型共享相同的 embedding,通过自蒸馏挖掘图像中更有用的区域。推理阶段仅保留教师模型。
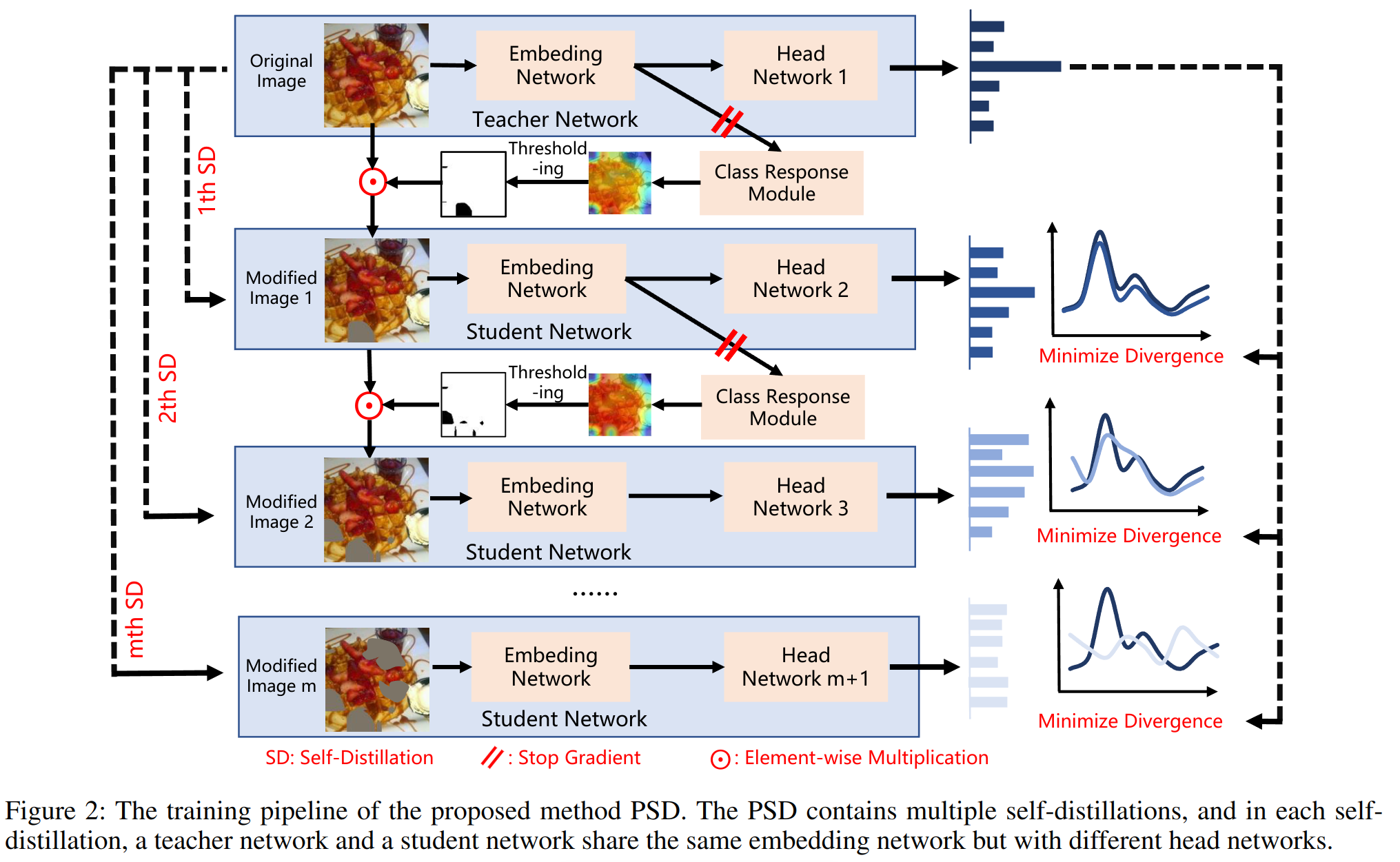
流程:输入原始图片 → ViT → T×D tokens → reshape 为 H×W×D feature map → 全局平均池化 → 全连接层 → Class Response Module → 根据阈值生成 mask → mask 与原图相乘 → 输入学生模型。
损失函数:
其中 为分类损失, 为定位损失, 为蒸馏损失。渐进性通过 的调度控制:
- 数据集:ETHZ Food-101、Vireo Food-172、ISIA Food-500
- Embedding 可用 CNN 或 Transformer(如 Swin Transformer)
8. 用 GPT-3 求解数学方程组
论文链接:Solving Math Word Problems concerning Systems of Equations with GPT-3
数据集:MWP2L
本文探究 GPT-3 在数学方程提取和求解上的能力,聚焦二元一次线性方程组:
- 问题分类:判断方程类型,准确率 80%-100%
- 方程提取:one-shot 精度 31%,3-shot 69%,fine-tune 后达 80%
- 问题生成:精度 33%-93%,取决于问题类型
五类问题:
| 类别 | 示例 |
|---|---|
| Sum and Difference | 两数之和与差 |
| Item and Property | 物品与属性(价格等) |
| Perimeter of Rectangle | 矩形周长 |
| Motion | 运动问题 |
| Mixture | 混合问题 |
9. 课程温度知识蒸馏(CTKD)
论文链接:Curriculum Temperature for Knowledge Distillation
代码:CTKD
中文解读:CTKD 中文解读
课程学习策略已广泛应用于计算机视觉和自然语言处理。相关工作包括 Curriculum Dropout(Morerio et al. 2017)。
10. SAM:锐度感知最小化
论文链接:Sharpness-Aware Minimization for Efficiently Improving Generalization
代码:SAM 官方 / 第三方实现
在 CIFAR-100 上取得 96.08% 准确率。
核心思想:现代模型参数量巨大,单靠 loss function 优化不足以支撑,会导致过多不同的解。SAM 提出不仅优化 loss,还要优化 loss 最小值附近的平滑度(曲率)。

定理(非正式表述):对于任意 ,以高概率有
右侧可拆解为:
依次为:锐度 + 损失 + 正则项。
SAM 损失函数:
本质上是最大最小化问题。数据并行可以放大 SAM 的性能。
11. 在线知识蒸馏的自适应层次分支融合
论文链接:Adaptive Hierarchy-Branch Fusion for Online Knowledge Distillation
13. 对比蒸馏用于任务对话系统的增量学习
论文链接:Class Incremental Learning for Task-Oriented Dialogue System with Contrastive Distillation
本文通过对比学习与蒸馏实现对话系统的增量学习:
- 仅更新与新任务相关的部分参数
- 对比学习:新任务数据作为锚点,原数据为负样本;上一阶段和新阶段模型对新任务数据的输出构成正样本对
- 复合损失:对比损失 + 交叉熵损失 + 蒸馏损失
- 动量更新:保证模型训练稳定性
14. 随机温度缩放改善人脸识别
论文链接:Improving Training and Inference of Face Recognition Models via Random Temperature Scaling
模型对无效输入仍以高置信度预测,这是不合理的。本文提出 RTS(Random Temperature Scaling),将温度与不确定性关联,引入 Gumbel 分布设计新的损失函数(类似 softmax),通过随机温度缩放影响模型的不确定性。
15. 无偏教师:半监督目标检测
论文链接:De-biased Teacher: Rethinking IoU Matching for Semi-supervised Object Detection
代码:De-biased-Teacher
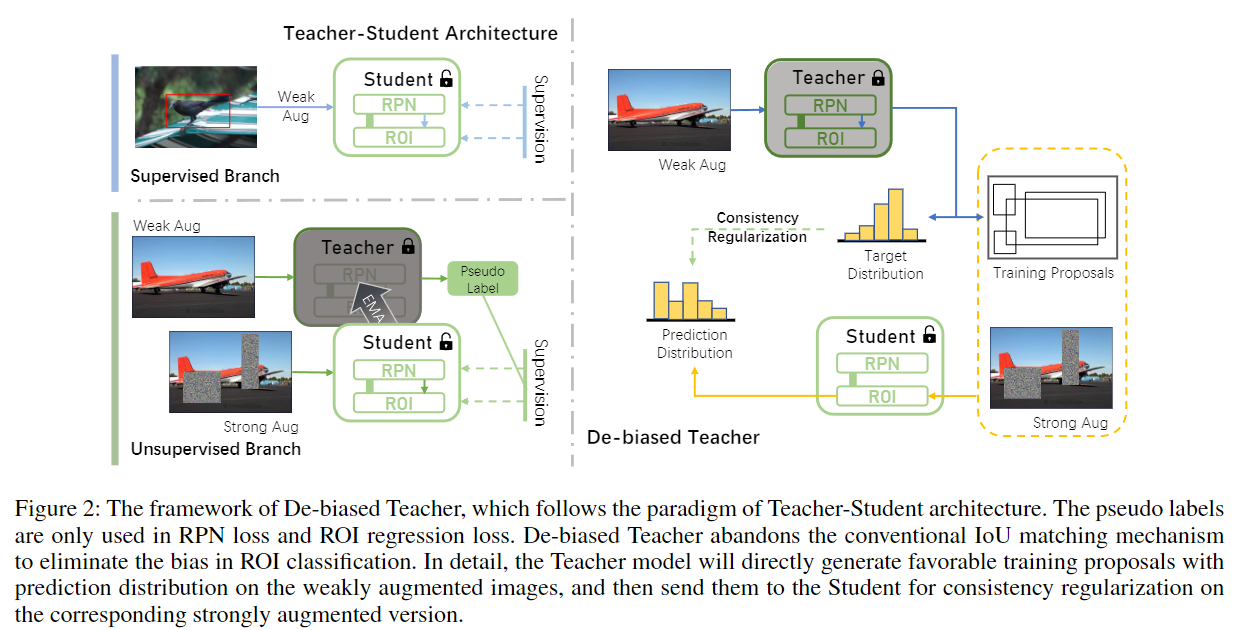
- 有标签图像直接通过弱增强训练学生模型
- 无标签图像由教师通过弱增强生成伪标签,学生通过强增强训练(一致性正则化)
- 教师模型通过自身与学生模型的动量更新
- 截断 softmax 尾部(阈值 0.05)

16. 分组知识蒸馏用于人脸识别
论文链接:Grouped Knowledge Distillation for Deep Face Recognition
将 logit 按阈值分组为三部分:
- Primary-KD:学习主要知识
- Secondary-KD:学习次要知识
- Binary-KD:确保教师与学生知识分布的一致性(本质是二分类问题)
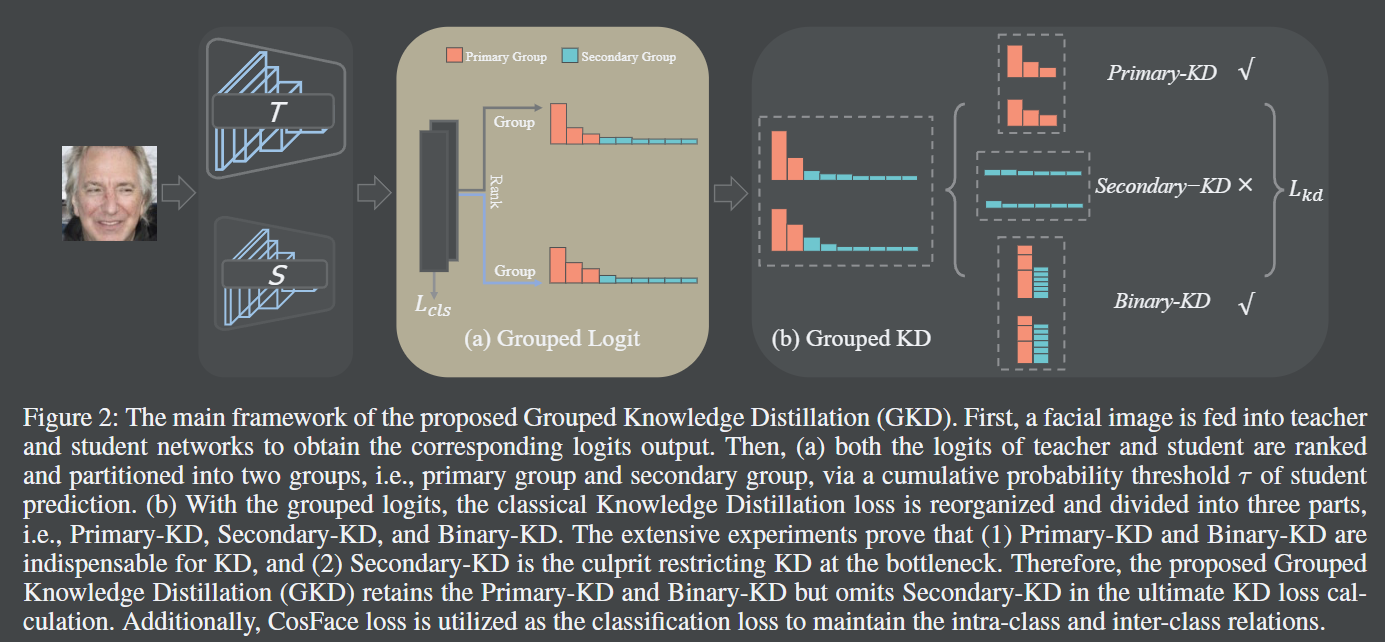
实验发现 Primary-KD 和 Binary-KD 是关键,Secondary-KD 贡献有限。最佳阈值为 0.93。
根据 student 输出排序后累加直到达到阈值的部分为 Primary-KD。作者实际代码中根据 teacher 排序,但实验表明根据 student 排序反而效果更好。
版权声明
- 作者: Corner430
- 标题: 论文阅读笔记
- 链接: https://corner430-ai-blog.vercel.app/blog/paper
- 许可协议: CC BY-NC-SA 4.0
除非另有说明,本文内容采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。