- 发布于
模型压缩
AI 摘要
- 作者

- 姓名
- Corner430
- 社交账号
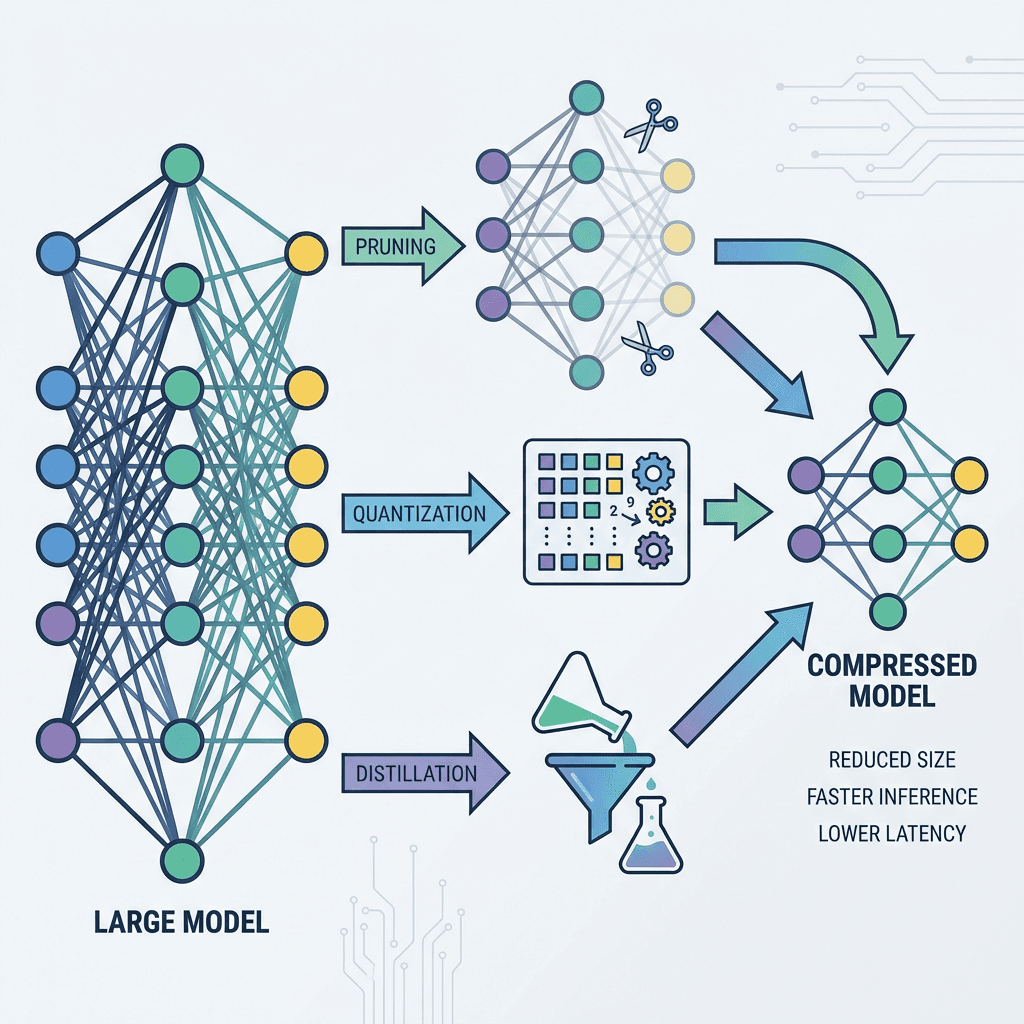
深度学习模型通常具有大量参数,部署时面临存储和计算资源的限制。模型压缩旨在减小模型体积、加速推理,同时尽可能保持模型精度。本文介绍五种核心的模型压缩技术。
模型压缩技术概览
- 网络剪枝(Network Pruning)
- 知识蒸馏(Knowledge Distillation)
- 参数量化(Parameter Quantization)
- 架构设计(Architecture Design)
- 动态网络(Dynamic Network)
1. 网络剪枝
基本原理
神经网络通常存在过参数化(over-parameterized)的问题,即大量冗余的权重或神经元。剪枝就是移除这些冗余部分。
剪枝流程
- 评估权重或神经元的重要性(例如,统计神经元在给定数据集上非零激活的次数)。
- 移除不重要的权重或神经元。
- 剪枝后精度会下降,通过在训练数据上微调来恢复。
- 反复进行剪枝和微调,直到满足要求。 不能一次剪枝太多,否则网络无法恢复。
为什么不直接训练小网络?
一个广泛认知是:小网络更难成功训练,大网络更容易优化。但这一观点存在争议:
- The Lottery Ticket Hypothesis(彩票假说)认为大网络中存在可直接训练的稀疏子网络。
- Rethinking the Value of Network Pruning 则对此提出了不同的看法。
权重剪枝 vs 神经元剪枝
- 权重剪枝:剪枝后网络结构变得不规则,GPU 难以加速。实际操作中通常将权重设为 0 以保持结构完整。参考 Learning Structured Sparsity in Deep Neural Networks,丢弃 95% 的权重仍可保持精度。
- 神经元剪枝:网络结构保持规则,易于实现和加速。
剪枝与压缩流水线
通过「剪枝 → 量化 → 哈夫曼编码」的三阶段流水线,可以大幅减小模型体积:
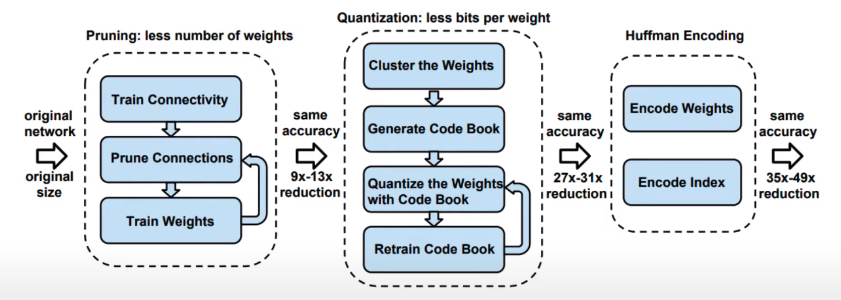
Deep Compression 展示了将 AlexNet 从 240MB 压缩到 6.9MB(35 倍压缩),且没有精度损失。
2. 知识蒸馏
知识蒸馏目前主要用于分类问题,将大模型(教师)的知识迁移到小模型(学生)中。
参考资源:
3. 参数量化
参数量化通过降低数值精度来减小模型体积:
- 使用更少的比特数表示数值。
- 权重聚类:通过 K-means 聚类将相近的权重合并。
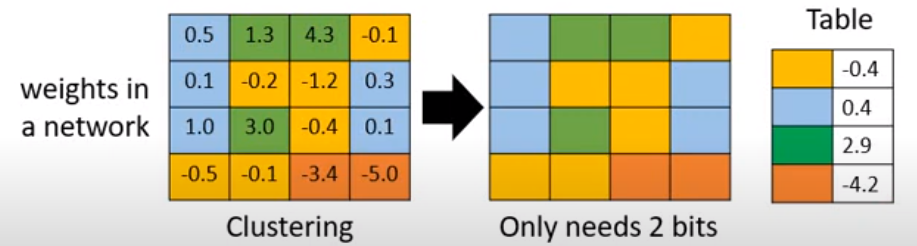
- 变长编码:对高频聚类用更少比特表示,低频聚类用更多比特(如哈夫曼编码)。
二值化权重(Binary Weights)
BinaryConnect 有时效果反而更好,因为二值化本质上是一种正则化手段。
4. 架构设计
低秩近似(Low Rank Approximation)
- 对于全连接层(FC),可以将其分解为两个较小的全连接层,减少参数量。本质上与矩阵分解相关。
- 对于卷积层:
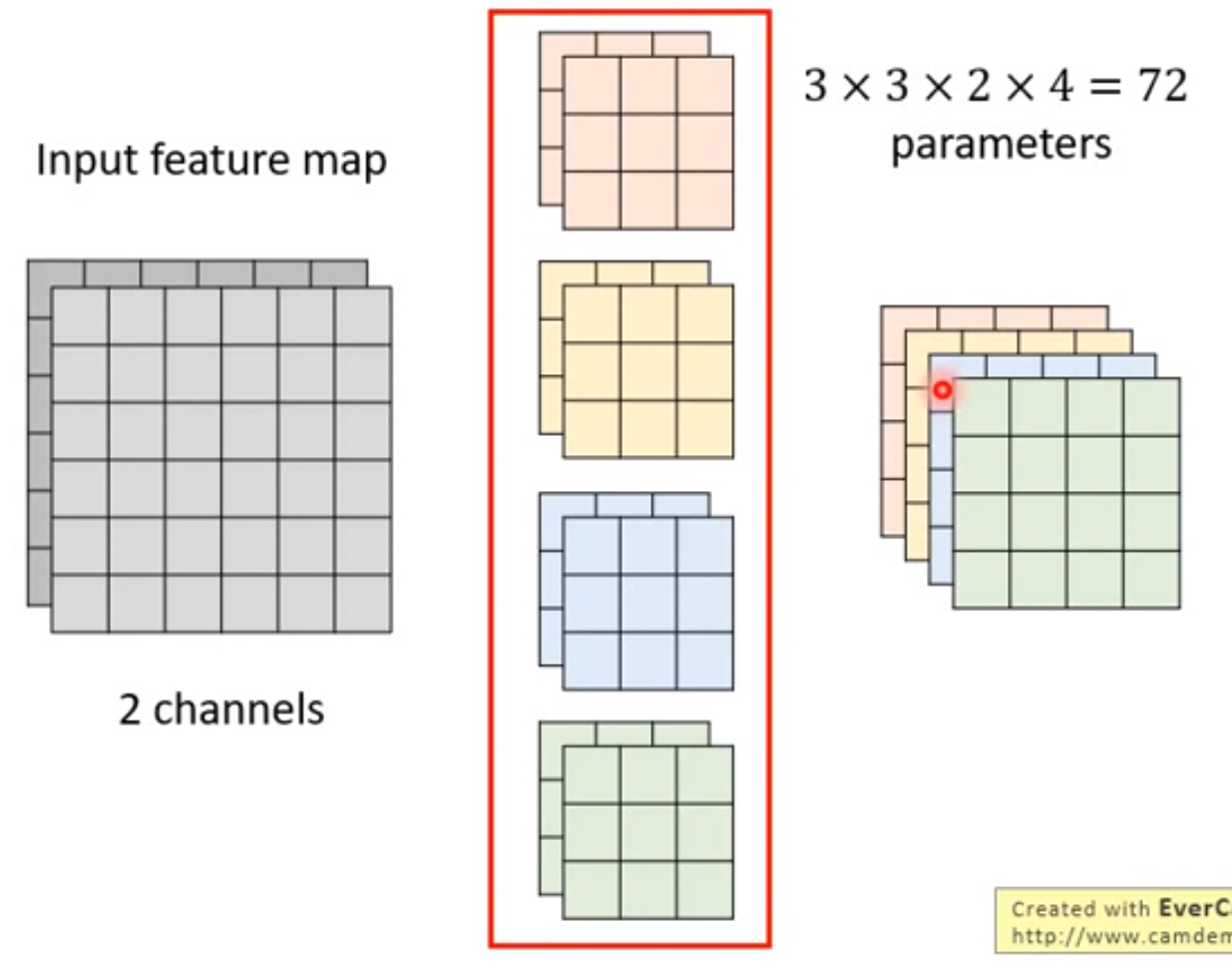
深度可分离卷积(Depthwise Separable Convolution)
参数量可降低 kernel_size × kernel_size 倍,存在参数复用。
相关模型
5. 动态网络
动态网络的核心思想是:网络能否根据输入的复杂度自适应调整所需的计算量?
可行方案包括:
- 训练多个分类器。
- 在中间层设置分类器(提前退出)。
参考 Multi-Scale Dense Networks for Resource Efficient Image Classification。
综合策略
不同压缩技术可以组合使用:
- 使用训练并剪枝后的网络权重初始化更小的网络。
- 权重剪枝置零后,保存非零权重,再通过知识蒸馏将知识迁移到更小的网络。
延伸阅读
- Robert T. Lange, Lottery Ticket Hypothesis: A Survey, 2020
- Cheng et al., A Survey of Model Compression and Acceleration for Deep Neural Networks, 2017
- Song Han, Lecture 10 - Knowledge Distillation, MIT 6.S965
版权声明
- 作者: Corner430
- 标题: 模型压缩
- 链接: https://corner430-ai-blog.vercel.app/blog/Model-Compression
- 许可协议: CC BY-NC-SA 4.0
除非另有说明,本文内容采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。